What is NL2SQL? Natural Language to SQL Explained for 2026
- Problem: NL2SQL systems score 85%+ on academic benchmarks but routinely collapse to 10–21% on real enterprise databases with hundreds of tables.
- Solution: Schema-aware, multi-step agent architectures push accuracy back to 86–95% on production workloads by indexing tables, validating SQL, and surfacing query reasoning before execution.
- Result: A working understanding of what NL2SQL really is, where it breaks, and a six-criterion scorecard for picking a tool that handles your actual schema instead of the demo one.
What is NL2SQL?
NL2SQL (Natural Language to SQL) is a class of AI systems that translate plain-English questions into executable SQL queries against a database. Modern NL2SQL systems combine large language models with schema-aware parsing to handle joins, aggregations, and complex business logic — replacing the manual SQL writing that has gated data access for two decades.
The capability matters because SQL never went away. Every BI dashboard, every operational report, and most data products still resolve to a SQL query somewhere. What changed in 2024–2026 is who writes it: schema-aware natural language to SQL agents now produce SQL that runs against production databases without hand-editing in the majority of cases, freeing analysts and business teams from the part of the job that was never the point.
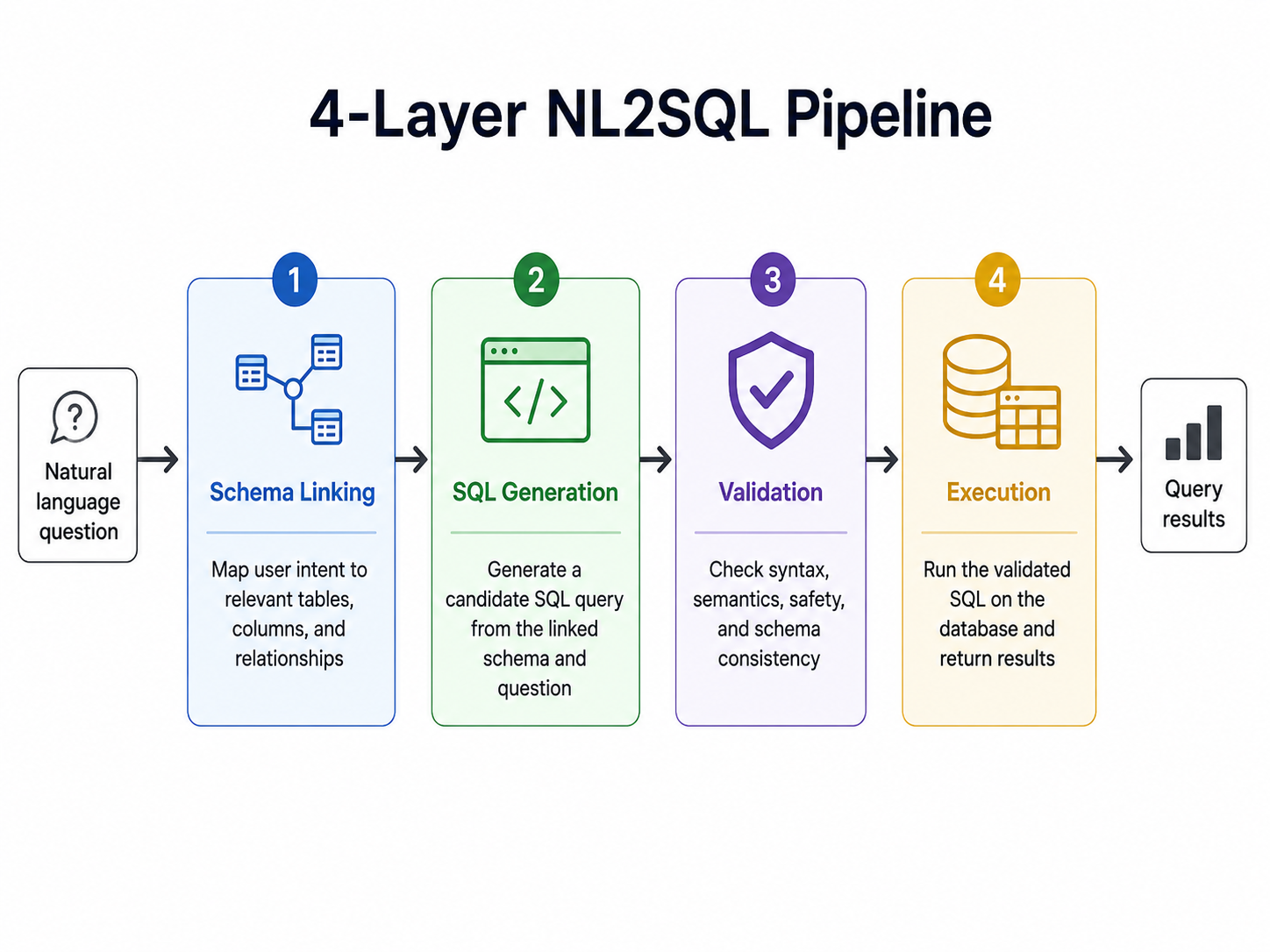
How NL2SQL works: 4 layers under the hood
NL2SQL is not a single model — it is a pipeline. The four layers below run in sequence on every question, regardless of which vendor you pick. Understanding what each one does (and where each one can fail) is the foundation for evaluating any tool in the category.
1. Schema linking
The first step is matching question terms to actual table and column names. "Customer revenue" might mean orders.amount summed by customer_id, or it might mean customers.ltv_estimate — only the schema can disambiguate. Schema-aware systems pre-index your tables, columns, and primary/foreign-key relationships so the matching is grounded rather than guessed. Tools that skip this step rely on stuffing raw schema into the LLM prompt and degrade sharply past 100 tables.
2. SQL generation
With schema in hand, an LLM proposes a SQL query. Frontier models in 2026 produce syntactically valid SQL almost always — the hard problem is no longer syntax, it is choosing the right join keys when multiple are plausible and the right time window when the question is ambiguous. This is where most accuracy is won or lost.
3. Validation
Before execution, a good NL2SQL system checks the generated SQL for obvious problems: referencing tables that do not exist, joining on incompatible column types, missing GROUP BY clauses. Some tools dry-run the query plan against the database; some surface the SQL to the user for human review. Tools without a validation surface let silent errors through.
4. Execution and interpretation
The query runs against the source database and returns rows. Better systems then summarize the result in natural language and offer follow-ups — "now segment by channel" — keeping schema and prior context across turns. The output is no longer a query string; it is an answer with the query attached as evidence.
If your tool stops at layer 2 (SQL generation), it is an NL2SQL helper. If it covers all four layers and the conversation across turns, it is a full AI data analyst. The distinction matters when you are picking what to buy.
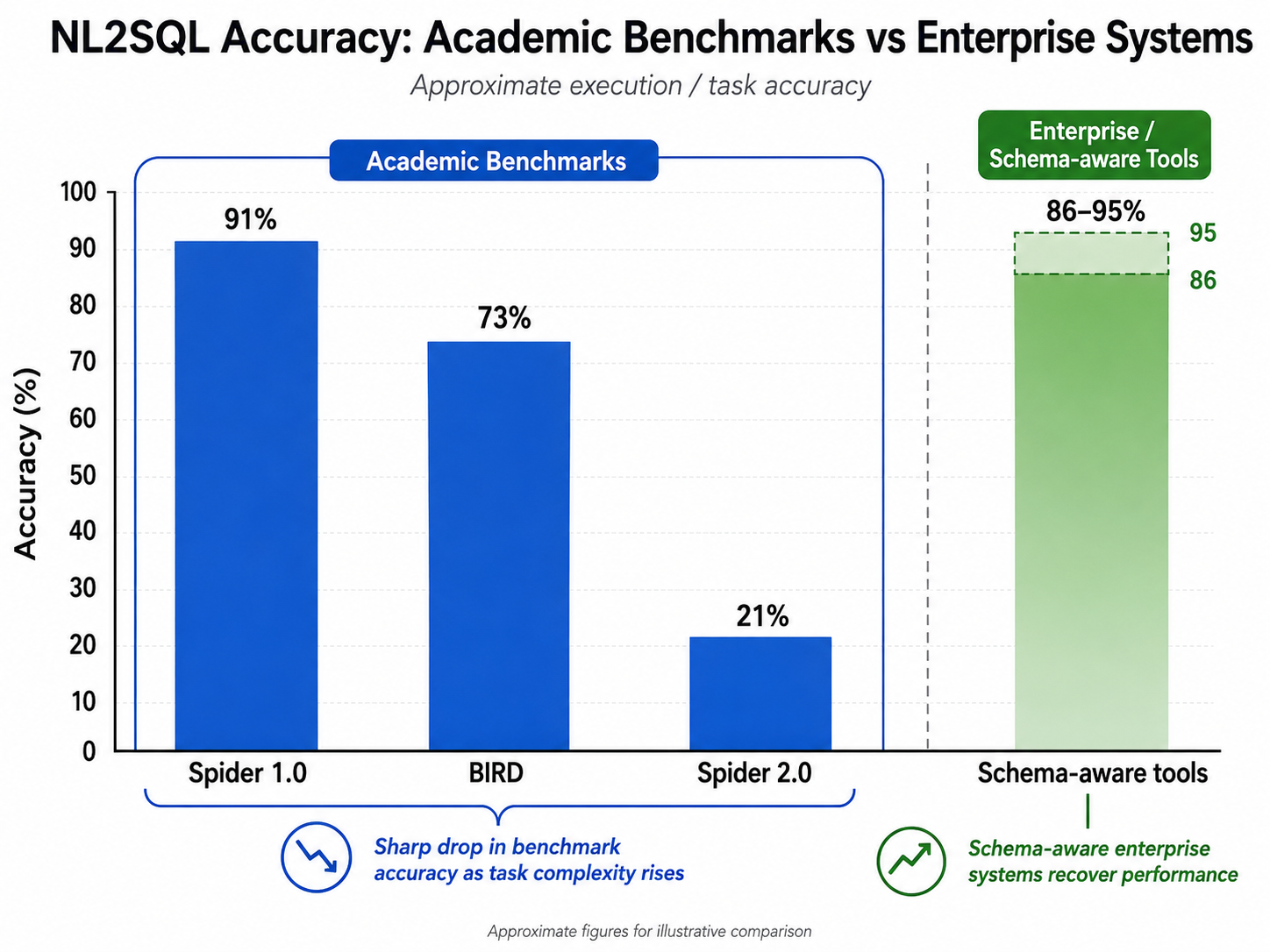
NL2SQL accuracy: the academic vs enterprise gap
The single biggest mistake in evaluating NL2SQL is reading a vendor accuracy number from an academic benchmark and assuming it predicts production performance. It does not. The gap between published numbers and real-world behavior is one of the most-studied issues in the field — and the one most likely to burn a buyer.
| Benchmark | What it measures | Best 2026 accuracy |
|---|---|---|
| Spider 1.0 | Clean academic schemas, single database | ~91% |
| BIRD | Realistic dirty data, single database | ~73% |
| Spider 2.0 | Real enterprise workflows, multi-database, 1000+ columns | ~21% |
| LLM-only on customer schemas | Production databases with business logic | 10–20% |
| Schema-aware enterprise tools | Same workloads with indexed schema + validation | 86–95% |
The gap is not the language model — it is everything around the language model. Spider 2.0 was specifically designed to expose this: it uses real customer databases with 1000+ columns, ambiguous business questions, and the kind of schema noise that lives in every production system. State-of-the-art LLMs solve 21% of Spider 2.0 tasks; they solve 91% on Spider 1.0. Between those two numbers is the entire reason naive NL2SQL pilots fail in the second month.
When a vendor cites an accuracy figure, ask which benchmark and which schema. If they cite Spider 1.0 without context, the number tells you nothing about how the tool will behave on your data.
Why production NL2SQL fails: 5 common failure modes
If you have ever piloted an NL2SQL tool and watched it work on the demo and break on your own database, one of the five modes below is almost certainly the cause. These show up across vendors and across schemas, and they explain why the accuracy cliff is so steep.
- Hallucinated columns. The LLM invents a table or column that does not exist. Common in tools without strict schema grounding. Symptom: SQL compiles in the editor, fails at runtime with
column not found. - Wrong join keys. Two tables can plausibly link on
customer_id,user_id, orexternal_id. The LLM picks the wrong one. The query runs, returns a number, and is silently wrong. - Misread time windows. "Last quarter" can mean the most recently completed quarter, the trailing 90 days, or this quarter's Q-to-date. Without explicit business definitions, the LLM picks one — usually the simplest, often the wrong one.
- Aggregation errors. Counting customers who placed an order is not the same as counting orders.
COUNT DISTINCTvsCOUNTis one of the most common silent errors in generated SQL. - Confident wrong. When the question is ambiguous or unanswerable, LLMs default to producing a plausible-looking answer rather than asking for clarification. Some tools now train models to abstain; most do not.
The 80% of NL2SQL tools that work on demo schemas all fail in similar ways on production. Picking a tool means picking how those failures get caught — schema indexing, validation layer, or a human-in-the-loop on the SQL surface.
NL2SQL vs Text-to-SQL vs Text2SQL: are they different?
Short answer: not really. NL2SQL, Text-to-SQL, text2sql, NL-to-SQL, and natural language to SQL all describe the same technical capability — translating a natural-language question into SQL. The naming variation matters mainly in two places.
- Academic literature uses "Text-to-SQL" because it fits the text-input-to-structured-output framing of NLP benchmarks (Spider 2.0, BIRD, Dr.Spider).
- Product marketing tends toward "NL2SQL" or "natural language to SQL" because it implies a broader natural-language interaction, not just one-shot text translation.
The brand Text2SQL.ai is a specific product; the term text2sql used generically refers to the same category. If you are searching for tools, treating these as synonyms is correct. If you are reading a research paper, "Text-to-SQL" usually signals a narrow benchmark frame and "NL2SQL" usually signals a system frame.
When NL2SQL is the right choice (and when it isn't)
NL2SQL is a productivity multiplier for exploratory analytical work, not a replacement for the BI layer. The teams that get the most value run NL2SQL alongside a SQL editor and a dashboard tool, not instead of them.
NL2SQL fits when:
- Multiple non-technical users need ad-hoc database access
- Analytical questions vary day-to-day — NL2SQL outperforms canned dashboards for exploration
- Schemas are too large for any one person to memorize (50+ tables, 500+ columns)
- Speed of iteration matters more than the marginal accuracy gain from a hand-written query
NL2SQL is the wrong choice when:
- The same 10 queries run repeatedly — a SQL view is faster and never wrong
- The question requires reasoning the database cannot answer (forecasting, decision rules outside the data, document Q&A that needs RAG rather than SQL)
- Regulatory environments require provable query auditability for every result
- Latency targets are sub-100ms — NL2SQL pipelines add 1–5 seconds of LLM overhead per question
If three or more of the "fits" bullets describe your team and none of the "wrong choice" bullets block you, an NL2SQL pilot is a high-ROI two-week experiment.
How to evaluate an NL2SQL tool: 6 criteria
When picking from the dozen-plus NL2SQL tools on the market in 2026, score each one on the six dimensions below. No tool wins on all six — pick the three that matter most for your team, then trial the top two on real data.
1. Schema awareness
Does the tool index your tables, columns, and primary/foreign keys before generating SQL, or does it prompt the LLM with raw schema each time? Indexed approaches reach 86–95% accuracy on production schemas; raw-prompt approaches usually fall under 50% on schemas with 100+ tables.
2. Multi-source support
Can the tool join across two databases, or across a database and a file? Most NL2SQL tools handle one source at a time. If your data lives in PostgreSQL plus Snowflake plus a CSV, multi-source matters from day one.
3. Validation and review surface
Does the tool show you the SQL before running it? Does it dry-run for column-existence checks? Tools without a review surface let silent errors through, which is the failure mode that erodes trust fastest.
4. Complex query ceiling
How does the tool handle 500+ line SQL with multiple JOINs, CTEs, and window functions? Most NL2SQL tools work well under 100 lines and degrade sharply past that. If your real workload has long queries, test those specifically.
5. Open-source vs closed
Open-source tools like Vanna AI let you self-host and audit; closed-source tools like Text2SQL.ai are faster to start but lock you into their pipeline. Pick based on your security and compliance constraints.
6. Pricing and free tier
NL2SQL tools range from $5/month (SQLAI.ai) to enterprise quotes (most). Almost all have free trials sufficient to evaluate accuracy on your data — use them. The price gap is rarely the differentiator; the accuracy gap usually is.
Score each tool 1–5 on the dimensions that matter for your team. A tool that scores 4+ on your top three dimensions, even if it scores poorly on the others, is the right pilot candidate. See our best NL2SQL tools 2026 guide for the full ranking we run against this rubric.
Test NL2SQL on your data in 60 seconds
Quick start: 3 steps to test NL2SQL on your data
The fastest way to evaluate any NL2SQL tool is to run it against your real schema, not the vendor's demo. The 30-minute test below catches more problems than a 30-day pilot does.
Do not test on a clean sample. Use a real schema with at least 20 tables and any naming inconsistencies your team has accumulated. The point is to see how the tool handles your actual mess, including legacy column names and undocumented join conventions.
Pull 10 questions from your team's Slack history or analytics ticket queue. Mix simple ("top customers by revenue last week") with complex ("of customers acquired in March, what is the 90-day retention by acquisition channel?"). Do not help the tool — ask the question exactly as a teammate would.
For each question, score 1 (correct SQL and correct answer), 0.5 (correct answer but SQL has a problem), or 0 (wrong answer or refusal). A tool that scores 8/10 on your real questions is production-ready. Most tools score 4/10 their first run; that is your real signal.
Run your first schema-aware NL2SQL query in under 5 minutes
InfiniSynapse connects directly to PostgreSQL, MySQL, Snowflake, BigQuery, MongoDB, and more. Ask a question in plain English. See the SQL, the result, and a written summary in one place.
Try InfiniSynapse free →FAQ
About this guide
Last updated: 2026-05-18
Methodology: Accuracy ranges cited in this guide come from the public Spider 2.0 and BIRD leaderboards (as of 2026-05) and the 2025 NL2SQL state-of-the-art survey published in VLDB. Tool capability claims are based on each vendor's published documentation; subjective fit calls ("when to use", "when not to") are flagged as judgment in the prose rather than presented as benchmark results.
Conflict of interest: InfiniSynapse is the publisher of this guide. The "Quick start" and "Try it" sections refer to our own product; competitive claims about other NL2SQL tools link to those vendors' sites so readers can verify directly.
Update cadence: Reviewed quarterly. Accuracy benchmarks, tool support matrices, and pricing figures refreshed every 90 days.